https://developer.nvidia.cn/blog/even-easier-introduction-cuda-2/
从图灵架构开始,在硬件上 shared memory 与 GPU 上的 L1 cache 共享同一块区域,同时 shared memory 与 Load/Store 单元交互也是直连的。
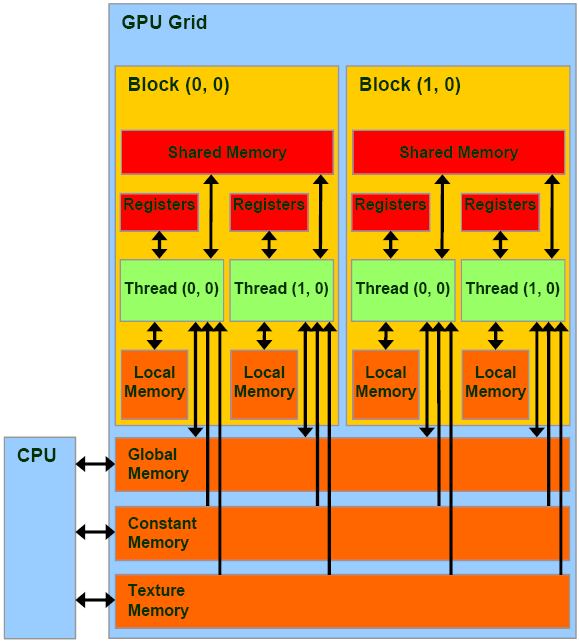
- 当我们在核函数内不加修饰的声明一个变量,此变量就存储在寄存器中
- CUDA中每个线程都有自己的私有的本地内存,属于片外存储
- 线程块有自己的共享内存,对线程块内所有线程可见;
- 常量内存只读,
__constant修饰,核函数一次读取会广播给所有线程束内的线程。 - 纹理内存是通过指定的缓存访问的全局内存,只读缓存包括硬件滤波的支持,将浮点插入作为读取过程中的一部分来执行
- 全局内存,常量内存和纹理内存有相同的生命周期
动态内存分配在堆上进行,静态分配在栈上进
对于全局内存的访存,一个warp在一次访存时,会同时访问连续的 32B 的地址 (一个 32 Byte 访问被称为一个 sector)。
访问全局内存中,让warp访问对齐的地址以及合并在连续块里的地址,会提高访存效率。

bank conflict是读写shared_memory时才有的问题
shared_memory 映射到大小相等的32个Bank上,Bank的数据读取带宽为32bit / cycle;
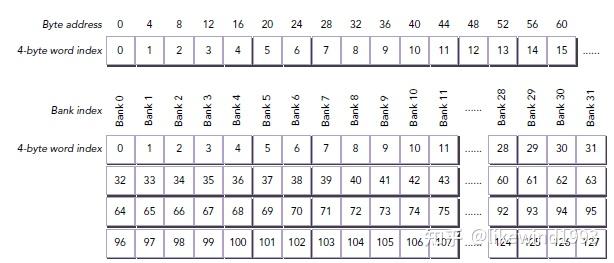
最理想的情况是一个WARP里32个线程每人一个bank,当多个线程读写同一个Bank中的数据时,拆分成 conflict-free requests,串行读写
但是当一个warp中的所有线程读写同一个地址时,会触发broadcast机制,此时不会退化成顺序读写
CUDA 最高支持 128 bit 的向量化访存,即一条指令请求 4 个 float 或 2 个 double 数据。但是向量化访存需要地址对齐,按32B对齐。
reinterpret_cast<int4*>(d_out)[i] = reinterpret_cast<int4*>(d_in)[i];GPU缓存不可编程,其行为出厂是时已经设定好了。GPU上有4种缓存:
- 一级缓存:每个SM都有
- 二级缓存:所有SM共用一个
- 只读常量缓存:每个SM一个
- 只读纹理缓存:每个SM一个
SM中的一级缓存和共享内存共享一个片上存储
一级二级缓存的作用都是被用来存储本地内存和全局内存中的数据,也包括寄存器溢出的部分。
nvcc add.cu -o add_cuda打印nsys日志
nsys profile -t cuda --stats=true ./add_cuda查看性能使用 nvprof 脚本,使用不同的metrics可以看不同的指标
nvprof --device 0 --metrics gld_efficiency ./test_cuda- grid是程序调用所有线程的集合,可以指定若干数量block,一个block通常包含256线程数,32个线程是一个warp,是最小的调度和执行单位。CUDA提供最高三维的线程组。
- 一个block由一个并行处理器SM控制,一个SM最多控制1024线程。
- 每个block有共享内存,同步器,SM的调度
// Run kernel on 1M elements on the GPU
add<<<numBlocks, blockSize>>>(N, x, y);
// Wait for GPU to finish before accessing on host
cudaDeviceSynchronize();- 第一个参数用于指定线程块的数量。如果总线程数 N 不是
blockSize的倍数,需要向上取整(round up)(N + blockSize - 1) / blockSize - 第二个参数:一个block中的线程数,通常是128或者256。
threadIdx.x是线程在block内当前线程的索引,blockDim.x包含块中的线程数,blockIdx.x是块的索引。线程的完整编号就是blockIdx.x * blockDim.x + threadIdx.x;。另外gridDim.x代表块的总数量。
可以使用下面的宏定义,来检查cudart函数运行错误
#define CHECK_CUDA(call) \
do { \
cudaError_t err=(call); \
if (err != cudaSuccess) { \
fprintf(stderr, "CUDA error at %s:%d: %s\n", __FILE__, __LINE__, cudaGetErrorString(err)); \
exit(EXIT_FAILURE); \
} \
} while(0)
CHECK_CUDA(cudaMemcpy(d_addr, h_addr, N * sizeof(float), cudaMemcpyHostToDevice));threadsPreBlock定义块大小,blocksPreGrim定义Grim大小
dim3 threadsPreBlock(16,16)
dim3 blocksPreGrim((M + threadsPreBlock.x - 1) / threadsPreBlock.x,
(N + threadsPreBlock.y - 1) / threadsPreBlock.y)Occupancy是每个 SM 能够同时调度的线程数量除以一个 SM 的最大可调度线程数量。由于寄存器总数的限制,如果一个线程使用寄存器太多,就导致SM能同时调度的线程变少。
计算访存比=浮点数计算次数/访存字节数,用来判断这个计算是算力瓶颈还是内存带宽瓶颈。
roof-line模型: 方案的理论性能上限=min(实际峰值算力, 带宽×计算访存比)
CUDA 采用单指令多线程SIMT架构管理执行线程,不同设备有不同的线程束大小,但是到目前为止基本所有设备都是维持在32,也就是说每个SM上有多个block,一个block有多个线程(可以是几百个,但不会超过某个最大值),但是从机器的角度,在某时刻T,SM上只执行一个线程束,也就是32个线程在同时同步执行,线程束中的每个线程执行同一条指令,包括有分支的部分。
同一个线程束里面的if和else会导致线程束分化,会导致性能下降。可以在条件中,尽量让同一个warp执行同一个分支,可以大幅度提高性能。
线程也是按照行相邻的,x维度相邻的32个线程是一个warp
c++中volatile修饰符可以让变量每次写回内存,绕过缓存,避免并发中读到还没从缓存到内存的脏数据
可以让变量在编译器就计算出结果,通常和 template 一起用,可以代替 #define 宏定义
通过优化矩阵的分块,提高计算访存比。
一个block分块计算访存比:
- 计算量:M_block * N_block * K_block * 2
- 访存量:(M_block + N_block) * K_block * 4 Byte (FP32)
当一个block计算64 * 64行列时,访存比达到16。此时在RTX 2080上进入Compute Bound。
正常情况block越大,
一个线程内计算[M_thread, K_block] @ [K_block, N_thread]。加入块的MNK是(128, 128, 8), 每个线程就是(8, 8, 8)。
for i in range(M):
for j in range(N):
for k in range(K):
c[i][j]+=a[i][k]*b[k][j]; 对于CPU来讲读数据每次会取一个cache line的数据,如果是连续访问就可以利用到cache,跳跃访问利用率就差。
再来看访存a[i][k]和b[k][j],ijk的顺序,让b矩阵不能连续访问,每次k++,b矩阵都要跳一整行的内存,利用不到cache line。
for k in range(K):
for i in range(M):
for j in range(N):
c[i][j]+=a[i][k]*b[k][j]; 如果是kij的顺序,每次存一个a[i][k]可以被利用N次,b[k][j]又可以连续访问,看起来就很完美了
如果每个k循环我们把N个B矩阵的b[k][j]和一个A矩阵的a[i][k]放在寄存器,就可以优化
cuda graph 和 kernal launch