![]()
Aplicativo desktop privado de chat com IA com suporte a LLMs locais.
Toda a inferência acontece na sua máquina — sem nuvem, sem compartilhamento de dados.

- O que é isso?
- Demo
- Principais Recursos
- Instalação e Configuração
- Como Começar a Usar
- Requisitos do Sistema
- Modelos Suportados
- Privacidade e Segurança
- Agradecimentos
- Licença
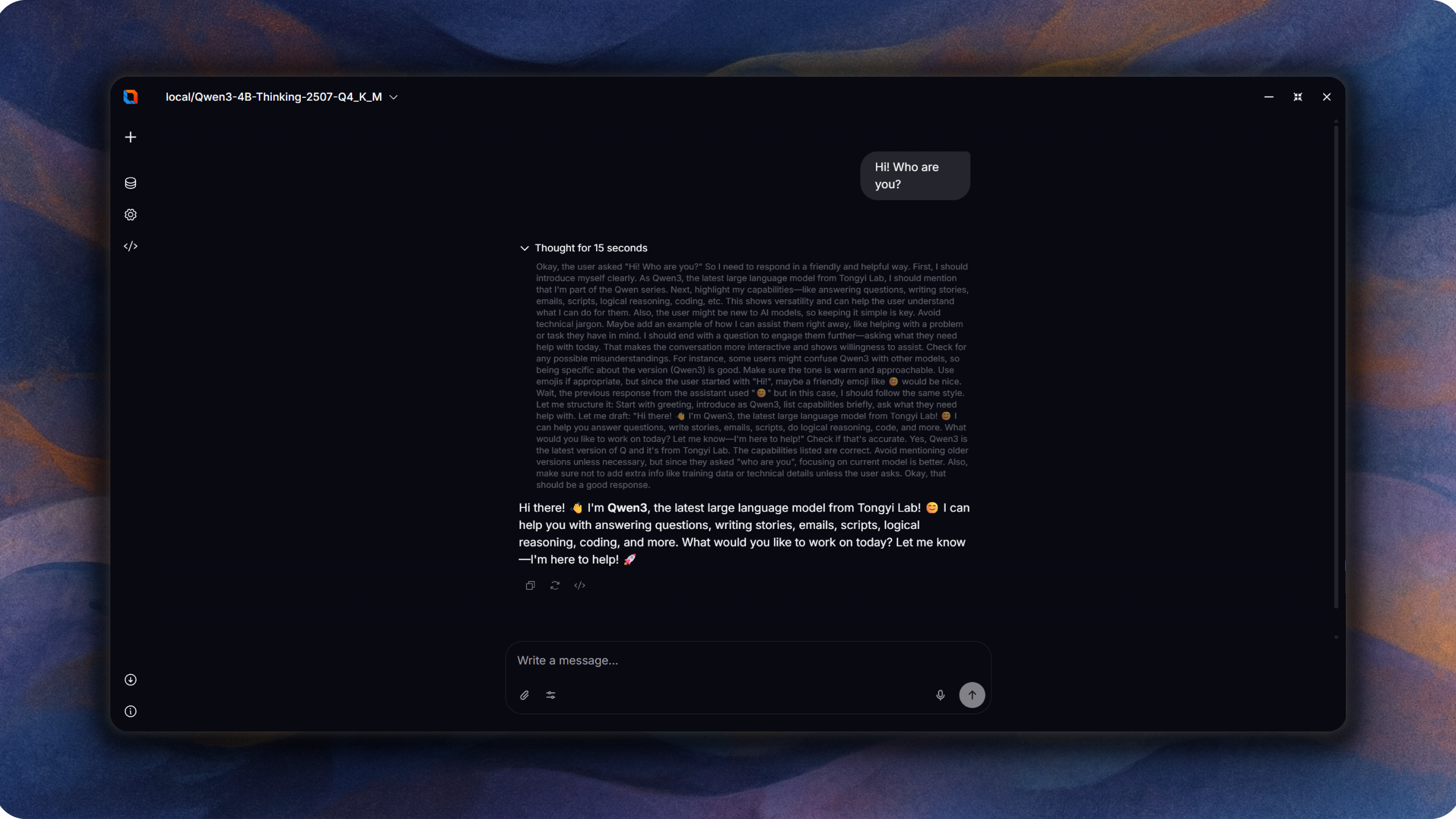
Oxide Lab é um aplicativo desktop nativo para executar modelos de linguagem grandes localmente. Construído com Rust e Tauri v2, oferece uma interface de chat rápida e privada sem necessidade de conexão com a internet ou serviços de API externos.
dem1.mp4
dem2.mp4
dem3.mp4
- Inferência 100% local — seus dados nunca saem da sua máquina
- Suporte a múltiplas arquiteturas: Llama, Qwen2, Qwen2.5, Qwen3, Qwen3 MoE, Mistral, Mixtral, DeepSeek, Yi, SmolLM2
- Formatos de modelo GGUF e SafeTensors
- Aceleração de hardware: CPU, CUDA (NVIDIA), Metal (Apple Silicon), Intel MKL, Apple Accelerate
- Geração de texto em streaming
- Interface multilíngue: inglês, russo, português brasileiro
- Interface moderna construída com Svelte 5 e Tailwind CSS
- Node.js (para build do frontend)
- Rust toolchain (para o backend)
- Para CUDA: GPU NVIDIA com CUDA toolkit
- Para Metal: macOS com Apple Silicon
# Instalar dependências
npm install
# Executar com backend CPU
npm run tauri:dev:cpu
# Executar com backend CUDA (GPU NVIDIA)
npm run tauri:dev:cuda
# Desenvolvimento com detecção de plataforma
npm run app:dev# Build com backend CPU
npm run tauri:build:cpu
# Build com backend CUDA
npm run tauri:build:cudanpm run lint # ESLint
npm run lint:fix # ESLint com correção automática
npm run check # Verificação de tipos Svelte
npm run format # Formatação Prettier
npm run test # Testes Vitestcargo clippy # Linting
cargo test # Testes unitários
cargo audit # Auditoria de segurança- Compile ou baixe o aplicativo
- Baixe um modelo compatível em formato GGUF ou SafeTensors (por exemplo, do Hugging Face)
- Inicie o Oxide Lab
- Carregue seu modelo através da interface
- Comece a conversar
- Windows, macOS ou Linux
- Mínimo 4 GB de RAM (8+ GB recomendado para modelos maiores)
- Para aceleração GPU:
- NVIDIA: GPU compatível com CUDA
- Apple: chip M1/M2/M3 (Metal)
Arquiteturas com suporte completo:
- Llama (1, 2, 3), Mistral, Mixtral, DeepSeek, Yi, SmolLM2, CodeLlama
- Qwen2/2.5, Qwen2.5/2 MoE
- Qwen3, Qwen3 MoE
Formatos:
- GGUF (modelos quantizados)
- SafeTensors
- Todo o processamento acontece localmente no seu dispositivo
- Sem telemetria ou coleta de dados
- Conexão com a internet não é necessária para inferência
- Content Security Policy (CSP) aplicada
Este projeto é construído sobre excelentes trabalhos open-source:
- Candle — Framework ML para Rust (HuggingFace)
- Tauri — Framework para aplicativos desktop
- Svelte — Framework frontend
- Tokenizers — Tokenização rápida (HuggingFace)
Veja THIRD_PARTY_LICENSES.md para atribuição completa de dependências.
Apache-2.0 — veja LICENSE
Copyright (c) 2025 FerrisMind
Tradução: Talita Maia Sousa