Apache beam and python pipelines for data ingestion
The main purpose of ingestion.py is to create a simple pipeline capable of using the csv file in data storage and processing it with Python and the data stream to insert the data into BigQuery.
It is necessary to first check how clean the data is, for this reason the data_quality.py pipeline helps to detect the null fields that might exist in the data source and report them in an error lookup table in a large query, so that the first step is to verify the csv with data_quality.py and after finishing a validation process continue inserting the data in BigQuery with ingestion.py
Step One: Check for Null Values
This is an example of how the data_quality.py pipeline could run on the Google cloud console:
user@cloudshell: python data_quality.py --project=main-ember-314713 --region=us-central1 --runner=DataflowRunner --stagein_location=gs://databucket1001/test -- temp_location=gs://databucket1001/test --input gs://databucket1001/f_medium_sessions.csv --output lake.errors_null --save_main_session
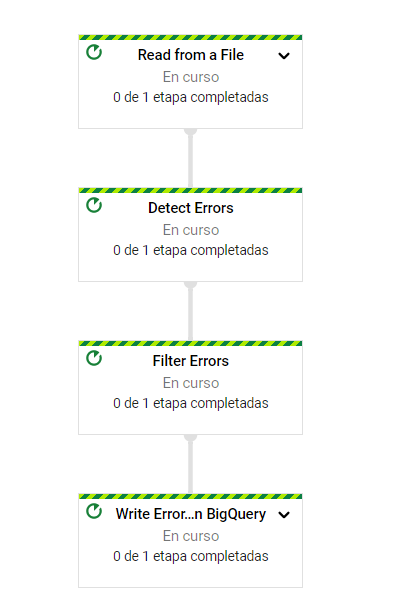
Second Step: Pipeline to Insert data into BigQuery
this is an example how the pipeline ingestion.py could be executed in Google Gloud console:
python ingestion.py --project=main-ember-314713 --region=us-central1 --runner=DataflowRunner --stagein_location=gs://databucket1001/test --temp_location=gs://databucket1001/test --input gs://databucket1001/f_event_sessions.csv --output lake.f_event_sessions --schema "profileId:STRING,dt:DATE,medium:STRING,eventCategory:STRING,landinpagepath:STRING,country:STRING,sessions:NUMERIC,users:NUMERIC" --dictionary "profileId,dt,medium,eventCategory,landinpagepath,country,sessions,users"
