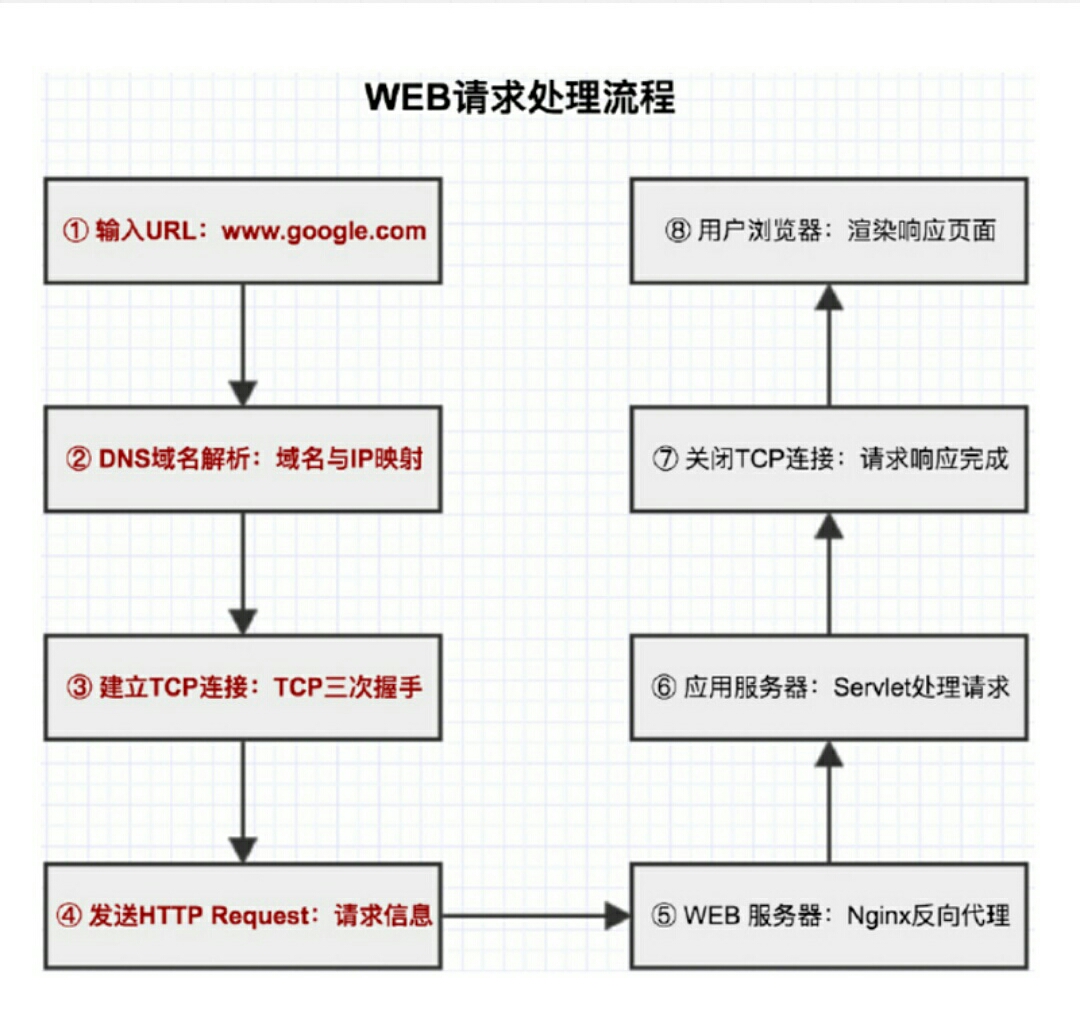
当一个用户在浏览器里输入www.google.com这个URL时,将会发生如下操作:
1 首先,浏览器会请求DNS把这个域名解析成对应的IP地址;
2 然后,根据这个IP地址在互联网上找到对应的服务器,建立Socket连接,向这个服务器发起一个HTTP Get请求,由这个服务器决定返回默认的数据资源给访问的用户;
3 在服务器端还有复杂的业务逻辑:服务器可能有多台,到底指定哪台服务器处理请求,这需要一个负载均衡设备来平均分配所有用户的请求;
4 请求的数据是存储在分布式缓存里还是一个静态文件中,或是在数据库里;
HTTP协议中的HTTP Header,控制着互联网上成千上万的用户的数据传输;
最关键的是,它控制着用户浏览器的渲染行为和服务器的执行逻辑;
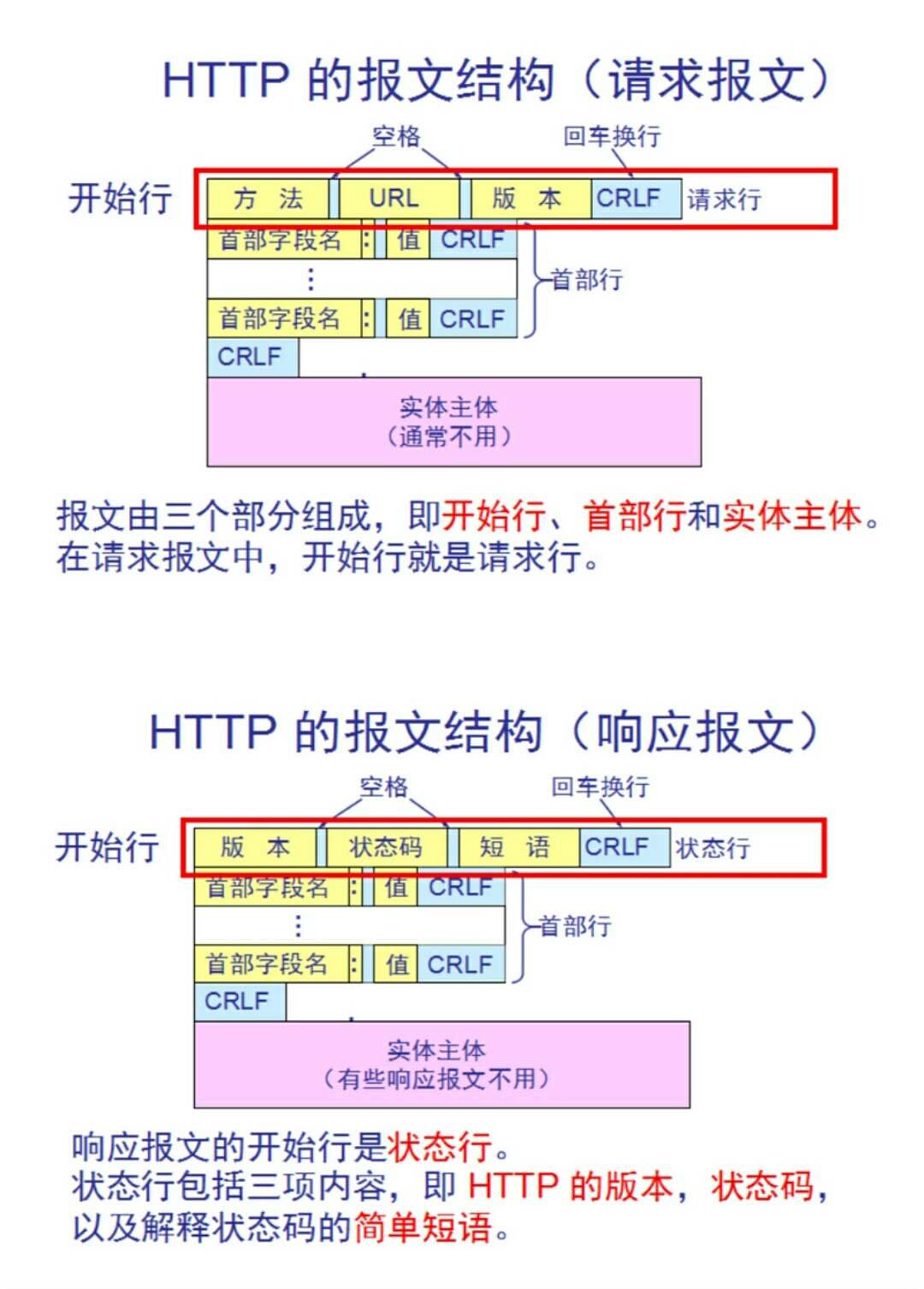
200: 成功
301: 请求的URL指向的资源已经被删除;
401: 需要输入账号和密码认证方能访问资源;
403: 请求被禁止;
404: 服务器无法找到客户端请求的资源;
500: 服务器内部错误;
当我们使用Ctrl+F5组合键刷新一个页面时,首先是在浏览器端,会直接向目标URL发送请求,而不会使用浏览器缓存的数据;
即使请求发送到服务端,也有可能访问到的是缓存的数据.
所以在HTTP的请求头中会增加一些请求头,它告诉服务端我们要获取最新的数据而非缓存;
最重要的是在请求头中增加两个请求项: Pragma:no-cache和Cache-Control:no-cache
浏览器本身是一个客户端,当你输入URL的时候,首先浏览器会去请求DNS服务器,通过DNS获取相应的域名对应的IP;
然后通过IP地址,找到IP对应的服务器后,要求建立TCP连接,等浏览器发送完HTTP Request(请求)包后,服务器接收到请求包之后才开始处理请求包,服务器调用自身服务,返回HTTP Response(响应)包;
客户端收到来自服务器的响应后,开始渲染这个Response包里的主体,等收到全部的内容随后断开与该服务器之间的TCP连接;
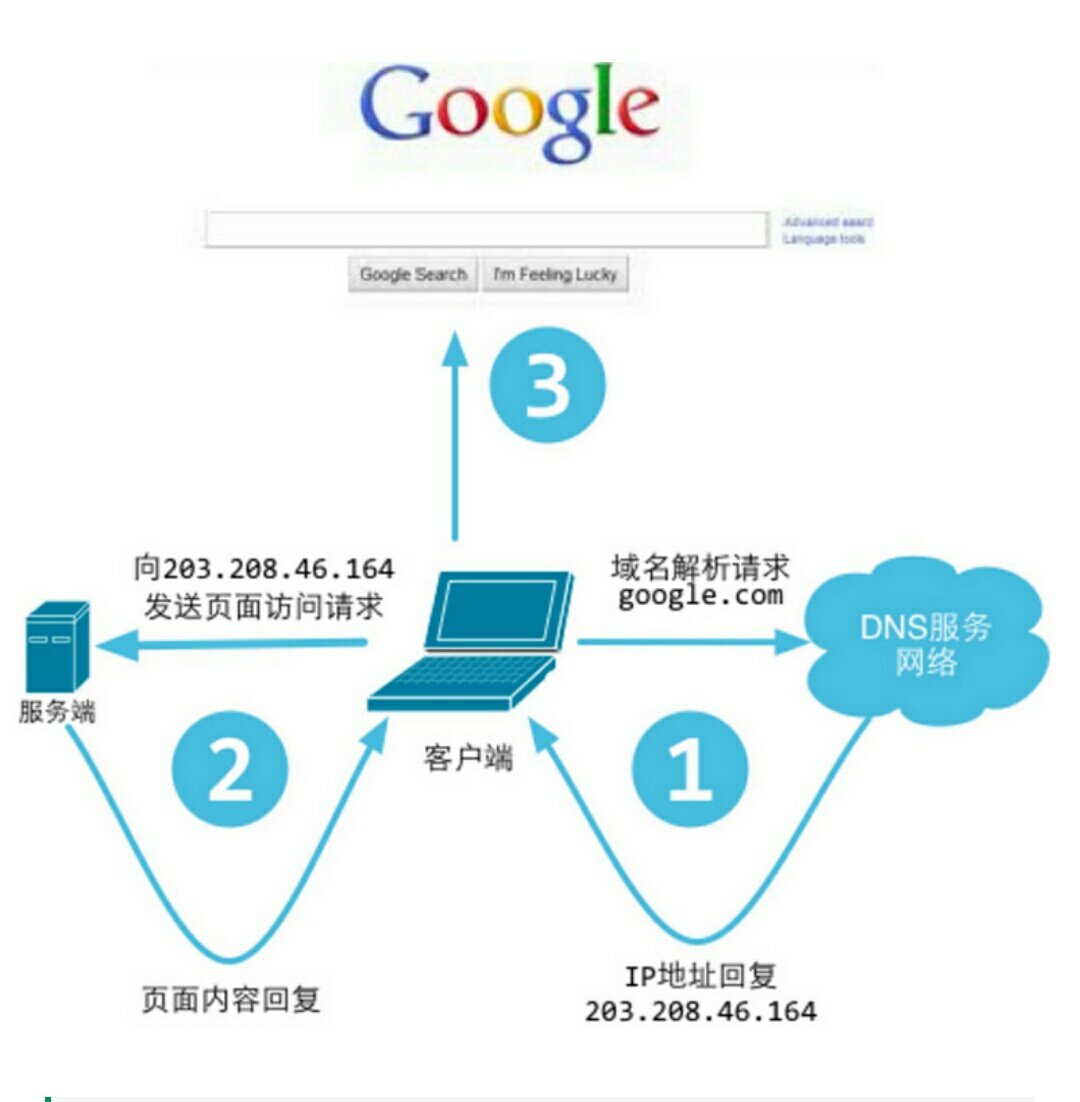
当用户在浏览器中输入域名,并按下回车后,DNS解析过程:
1.浏览器先查缓存,若缓存中有域名对应IP地址,则解析结束;
2.若浏览器缓存中没有,浏览器会查询操作系统中缓存缓存是否有这个域名对应的DNS解析结果;(hosts 文件);
3.如果在本机中仍然无法完成域名的解析,则会真正请求域名服务器来解析这个域名;
…
4.解析结果返回给用户,用户根据TTL值缓存在本地系统缓存中,域名解析过程结束;
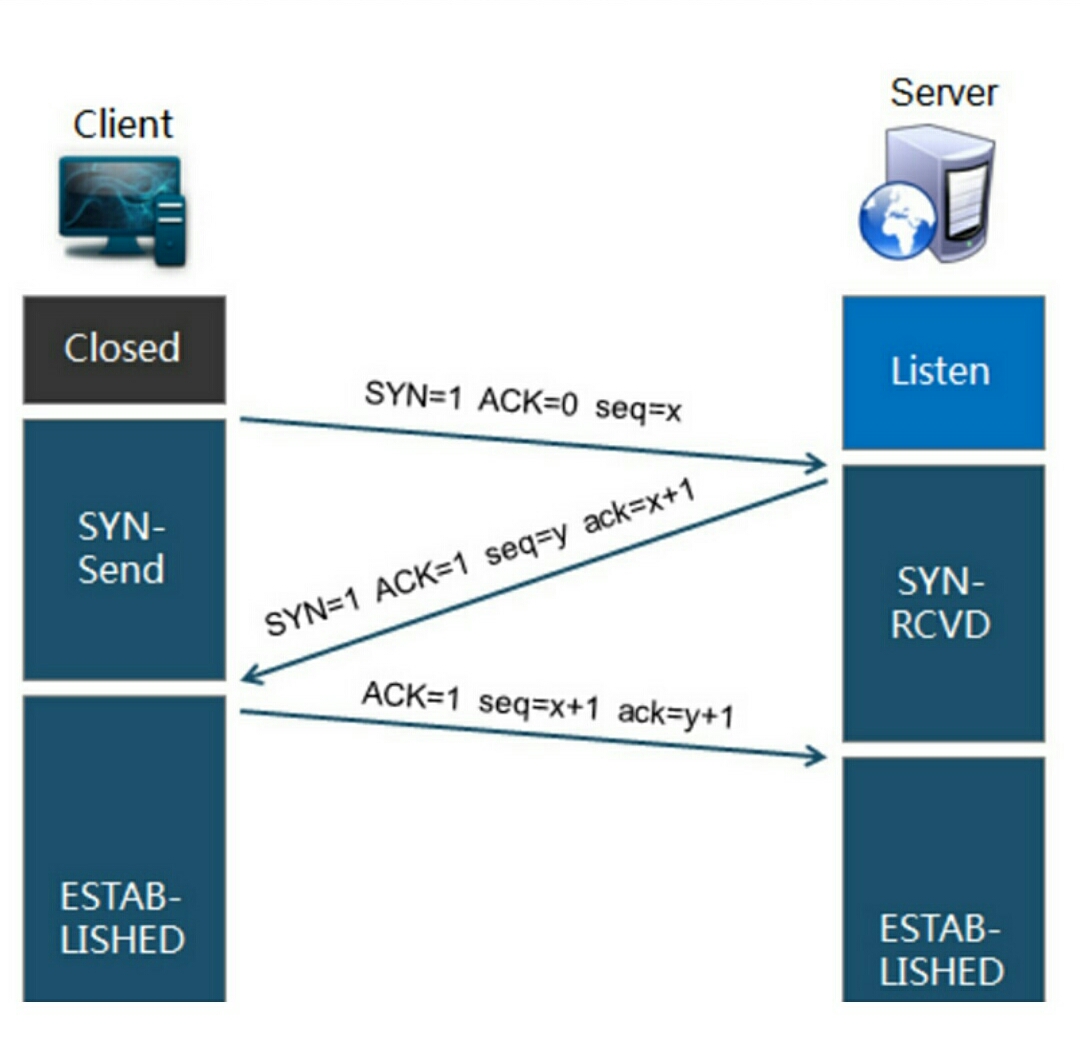
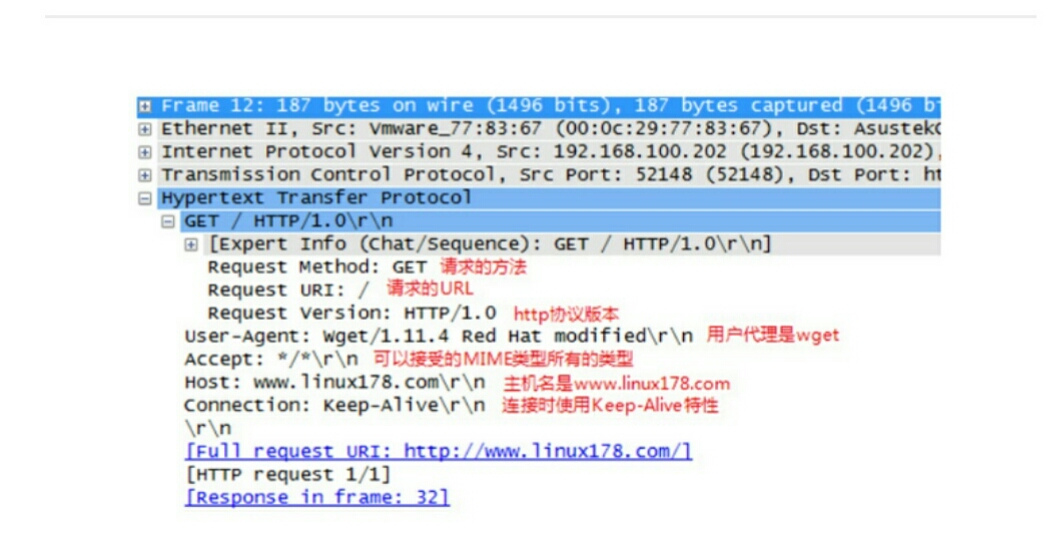
经过TCP3次握手之后,浏览器发起http的请求;
html → head → title → #text(网页标题) → style → 加载样式 → 解析样式 → link → 加载外部样式表文件 → 解析外部样式表 → script → 加载外部脚本文件 → 解析外部脚本文件 → 执行外部脚本 → body → div → script → 加载脚本 → 解析脚本 → 执行脚本 → img → script → 加载脚本 → 解析脚本 → 执行脚本 → 加载外部图像文件 → 页面初始化完毕
客户端浏览器向服务器发送请求URL;
服务器接收到该浏览器发送的请求;
服务器解析请求的URL,根据URL确定请求的目标资源文件,这个资源文件通常是一个动态页面(如ASP,PHP,JSP,ASPX等文件)的网络地址;
Web服务器根据动态页面文件的内容和URL中的参数,调用相应的资源(数据库数据或图片文件等等)组织数据,生成HTML页面;
生成HTML文档后,服务器响应浏览器的请求,将生成的HTML文档发送给客户端浏览器;
浏览器接收服务端发出的请求得来HTML文档;
浏览器对HTML文档进行解析,并加载相关的资源文件;
浏览器解悉完HTML文档后,会进行呈现;同时也会向服务器发送请求来请求其它相关的资源文件;
服务器接到浏览器对资源文件的请求,将相应的资源文件响应给客户端浏览器;
客户端浏览器将接收服务器发送的资源文件,整理并呈现到页面中;
在进行页面呈现的时候,浏览器会从上到下执行HTML文档,当遇到相应的页面脚本的时候,会对脚本进行分析,并解释执行相应的脚本代码;