| title | Welcome to SGLang | ||||
|---|---|---|---|---|---|
| description | High-performance serving framework for large language and multimodal models. | ||||
| keywords |
|
||||
| mode | wide |
<a class="github-button" href="https://github.com/sgl-project/sglang" data-size="large" data-show-count="true" aria-label="Star sgl-project/sglang on GitHub"
Star <a class="github-button" href="https://github.com/sgl-project/sglang/fork" data-icon="octicon-repo-forked" data-size="large" data-show-count="true" aria-label="Fork sgl-project/sglang on GitHub"
Fork
<script async defer src="https://buttons.github.io/buttons.js"></script>SGLang powers large-scale production deployments, generating trillions of tokens each day across more than 400,000 GPUs worldwide. It is hosted under the non-profit open-source organization LMSYS.
SGLang is an inference framework meant for production level serving. It is designed to deliver low-latency and high-throughput inference across a wide range of setups, from a single GPU to large distributed clusters.
Install SGLang with pip, from source, or via Docker on your preferred hardware platform. Launch your first model server and send requests in minutes with OpenAI-compatible APIs.{/* BEGIN_LMSYS_SGLANG_BLOG_CARDS */}
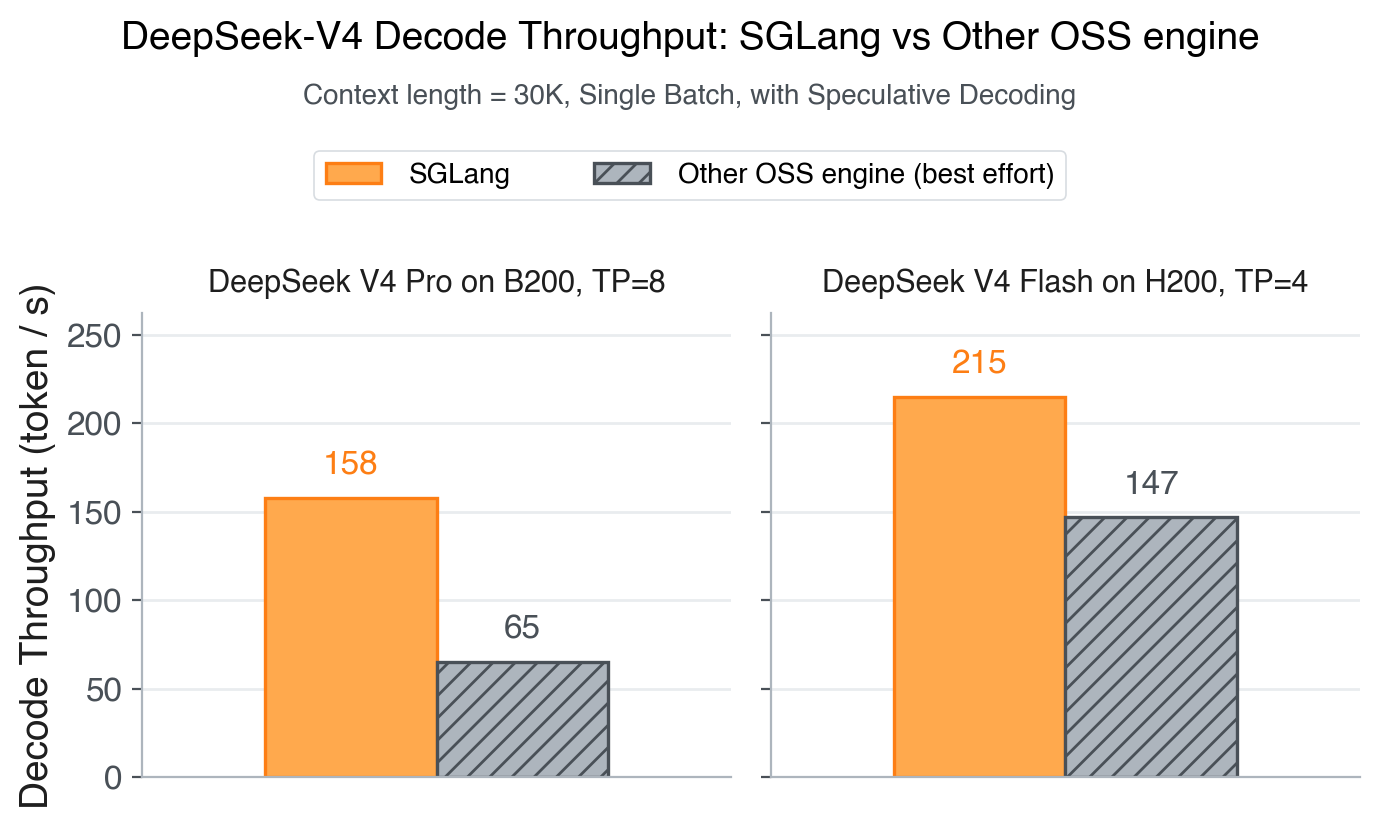
{"DeepSeek-V4 on Day 0: From Fast Inference to Verified RL with SGLang and Miles"}
{"April 25, 2026"}
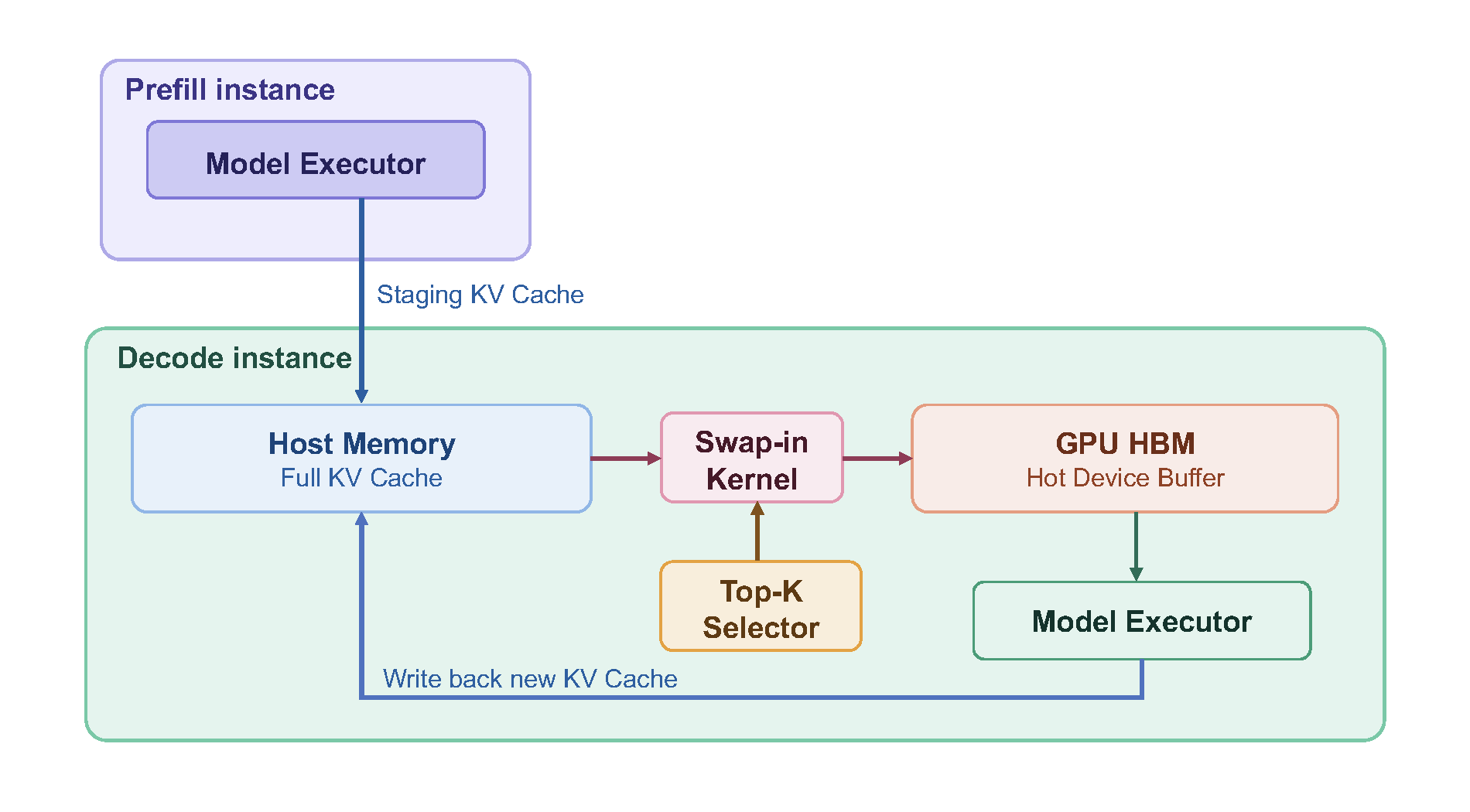
{"HiSparse: Turbocharging Sparse Attention with Hierarchical Memory"}
{"April 10, 2026"}

{"Highlights of SGLang at NVIDIA GTC 2026"}
{"March 31, 2026"}
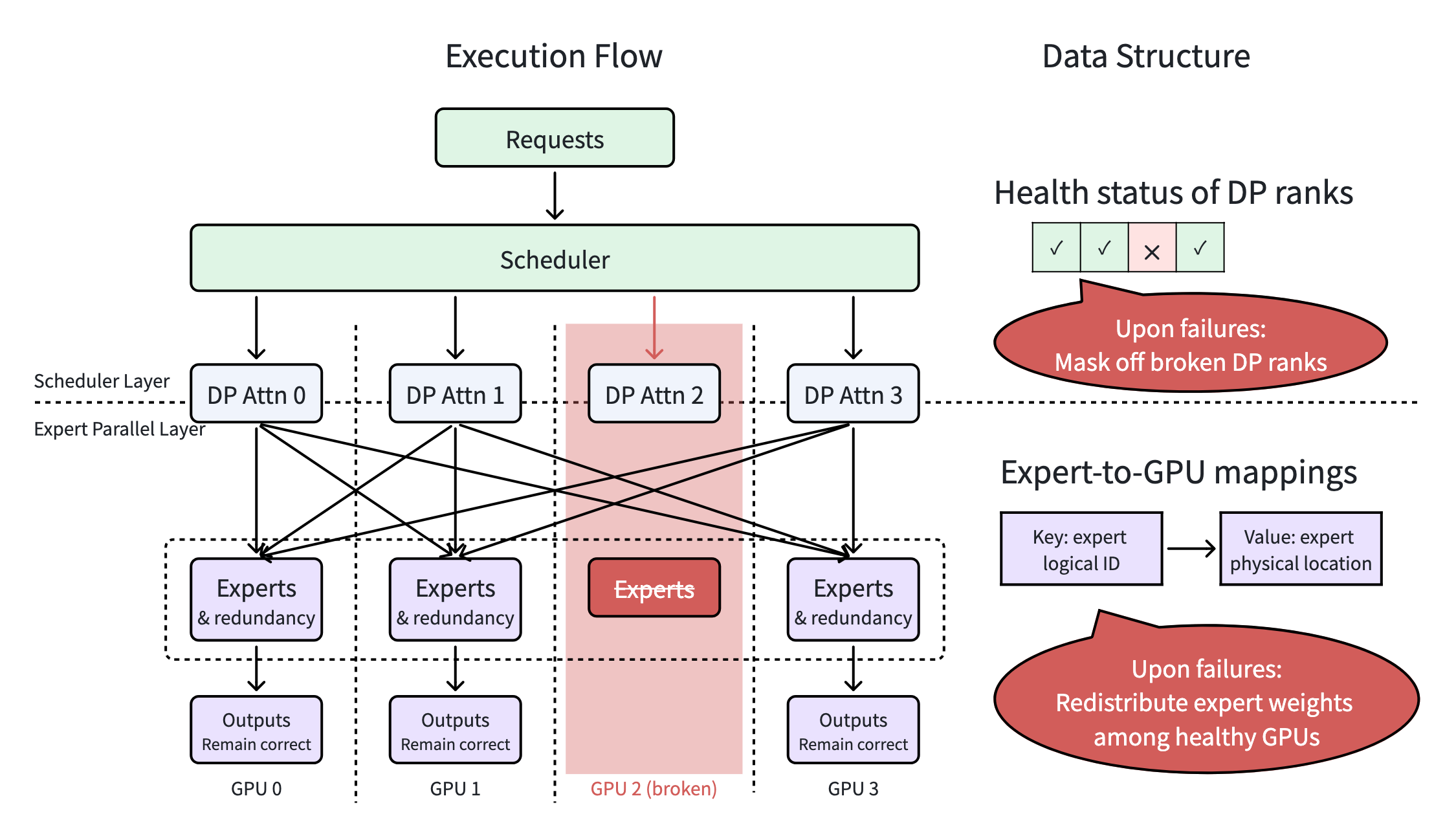
{"Elastic EP in SGLang: Achieving Partial Failure Tolerance for DeepSeek MoE Deployments"}
{"March 25, 2026"}

{"ROCm Support for Miles: Large-Scale RL Post-Training on AMD Instinct\u2122 GPUs"}
{"March 17, 2026"}

{"SGLang Adds Day-0 Support for NVIDIA Nemotron 3 Super for building High-Efficiency Multi-Agent Systems"}
{"March 11, 2026"}
Stay connected